1. 프로젝트 핵심 메시지 지난 3년간 작업했던 AI 프로젝트 260개를 지우고 깨달았습니다. 결국 골드러시 시대에 돈을 버는 건, 청바지와 곡괭이를 파는 사람이라는 것을. 수많은 AI 강의와 전자책이 쏟아지지만, 정작 당신의 통장은 그대로이지 않나요?우리는 AI로 수백 개의 프로젝트를 기획하고 엎어보며 하나의 …

작심삼일 – 만다라트 목표달성 워크샵을 하기위해 다시 만다라트 소스를 열어봤습니다. 그 사이에 별의 별걸 다 해서 제가 쓴 글을 만다라트로 만든 것도 있고 llm 테스트한 것도 있고 이것저것해서 52만 파일이 생겼습니다. 만든지 2년 만에 저만 쓰고 저만 놀았으니 이제 슬슬 …
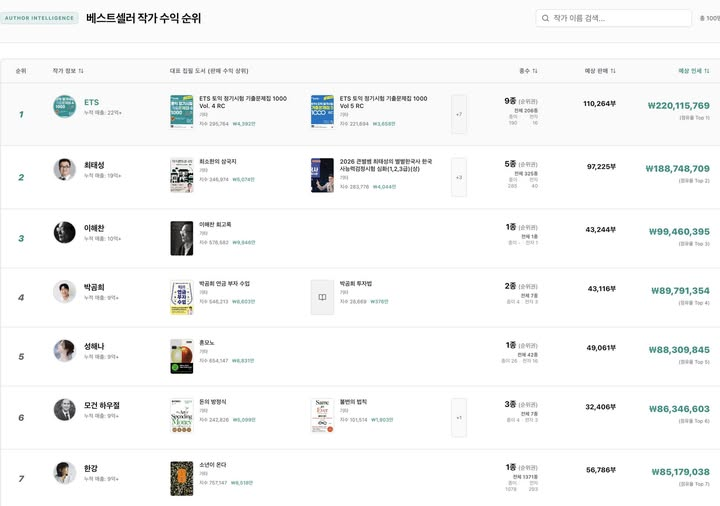
ETS 관련 출판사 매출: 30억+ 추정인세 ₩302,167,024 베스트셀러 200위 안에 18종 최태성 관련 출판사 매출: 24억+ ₩240,531,584 14종(순위권) 전체 325종 베스트셀러 작가들은 얼마나 많은 책을 썼고 그중에 베스트셀러 100위 안에 몇권을 올려놓고 있는가? 그냥 22억 인세 받는 곳은 제외하고 최태성 …
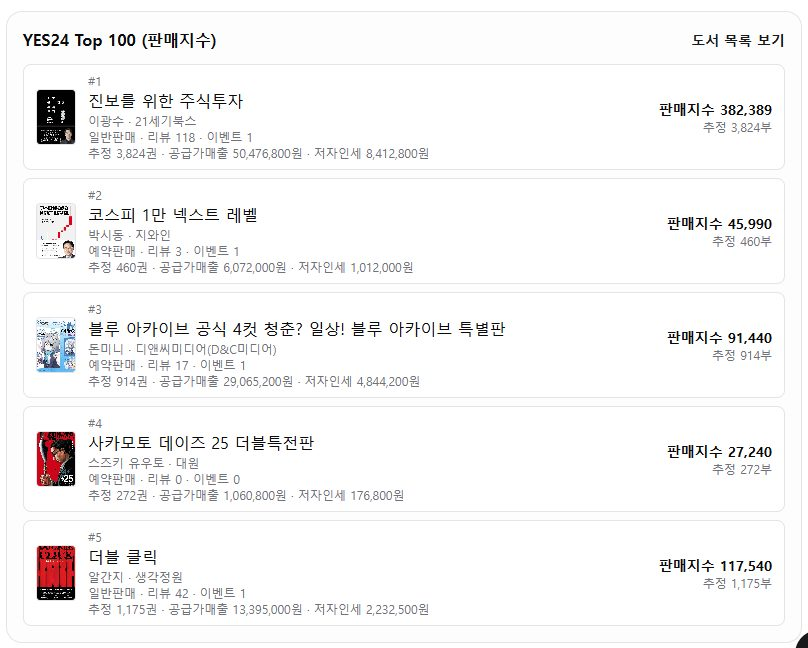
남들은 책팔아 얼마나 벌까? 라는 서비스를 만들었습니다. 많이 벌겠죠… 그래서 어떻게 광고해서 어떻게 키워가는지를 찾아내는 서비스입니다. 진보를 위한 주식투자 Y에서 저자인세 8,412,800 원이면 *4 를 하면 3200만원정도 나오겠네요… 주식보다 나을지도 응?!? 박시동씨는 예판으로 대략 4백? 서평이 별로 없죠~ https://bookfactory.kr/
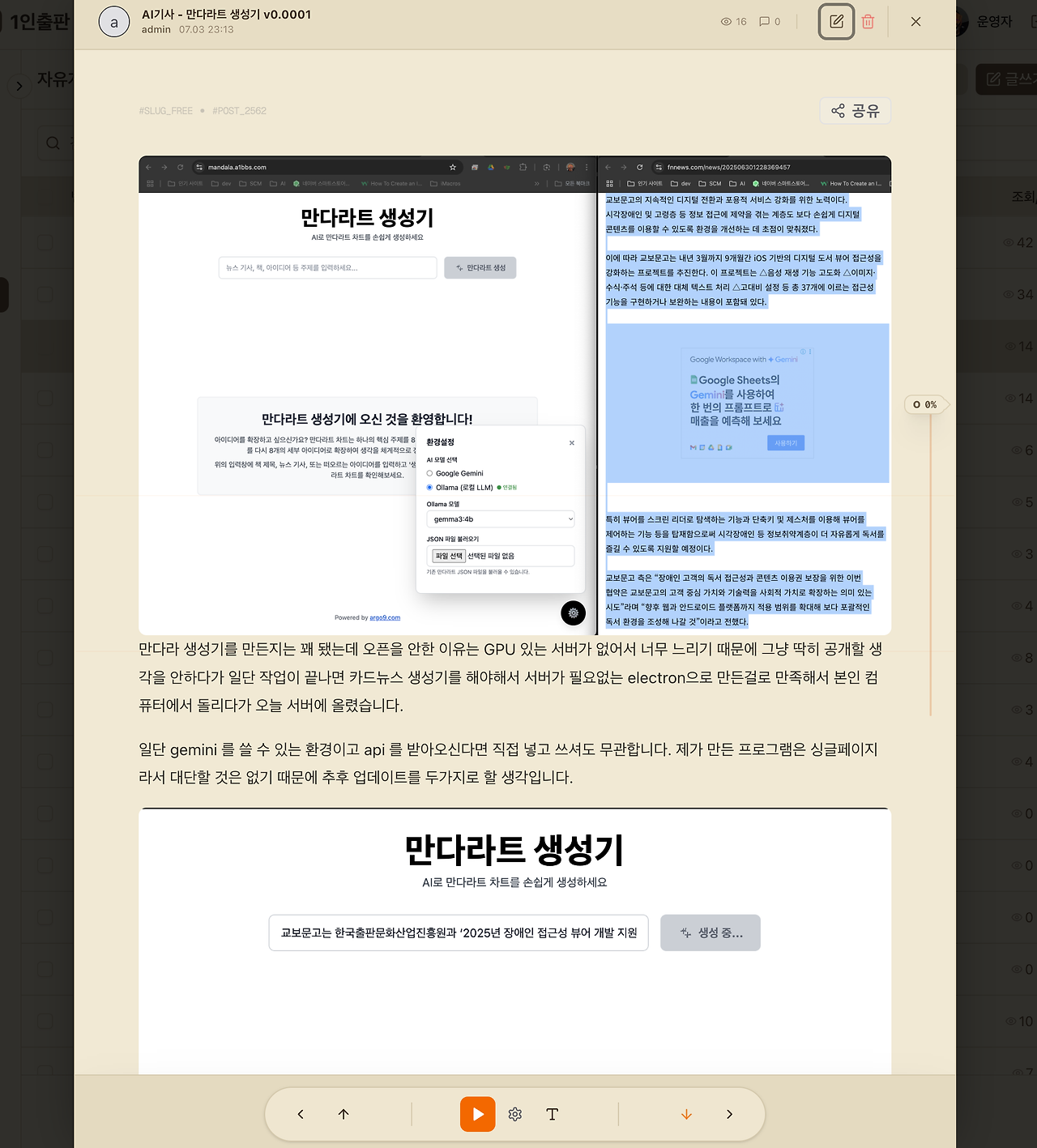
수퍼토닉2 음성합성 게시판 + ebook 변환기를 만들어봤습니다. 게시판에 음성합성을 붙이긴 했는데 아무래도 뉴스 같은게 아니라 블로그라서 멋대로 쓴 게시글이 엉망이지만 일단 노안용으로 글자도 키울 수 있고 이것저것 전자책 뷰어처럼 만든 게시판입니다. 처음에는 nextibase 로 만들었다가 그냥 mysql -> sqlite 로 …
깃허브 액션 기다리다 속 터져서… 그냥 직접 배달하는 봇을 만들었습니다. 요즘 Github Actions 돌려놓고 멍하니 모니터만 바라보는 시간이 너무 길더라고요. 무료 티어라 그런가, 빌드 한번 걸어놓으면 세월아 네월아… 게다가 ubuntu <-> windows <-> mac 한 번에 된적이 없어요 ㅠㅠ 성격 …
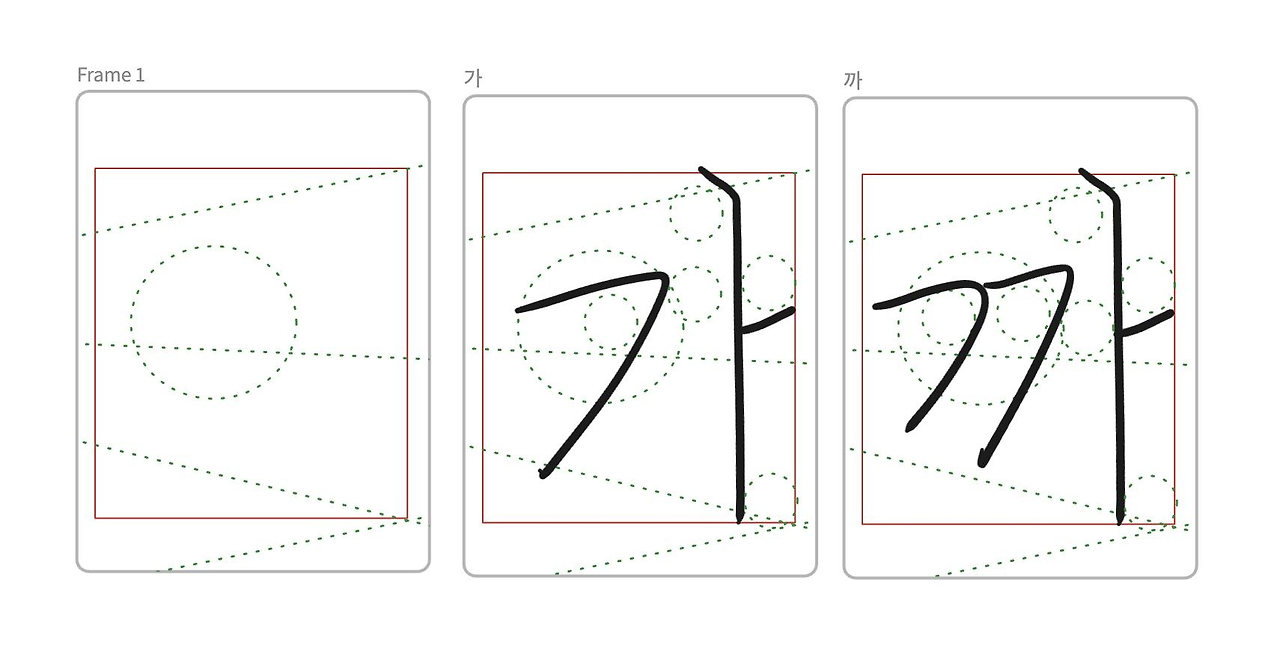
지난 3년간 만들던 획기반 손글씨 폰트 에디터 일단 손글씨 쓰면 공간 분석해줍니다. 그리고 손글씨에서 폰트로 바꾸면서 두께와 획 스타일을 변경해서 폰트를 다양하게 찍어낼 수 있습니다. 획기반의 2가지 기술을 사용해서 영상자막용 애니메이션 폰트 작업이 순조롭게 마무리 되어 갑니다. 이제 불꽃으로 AI가 …
모든 것이 ‘숫자’가 된 세상에서 우리의 ‘가치’를 지키는 법 우리는 그 어느 때보다 ‘다양성’을 외치는 시대에 살고 있습니다. 하지만 역설적이게도 사회가 세분화될수록 우리는 ‘연봉’, ‘팔로워 수’, ‘랭킹’이라는 단일한 수치에 더 필사적으로 매달립니다. 각자의 취향이 존중받는 유토피아를 꿈꿨건만, 현실은 주말의 취미조차 …
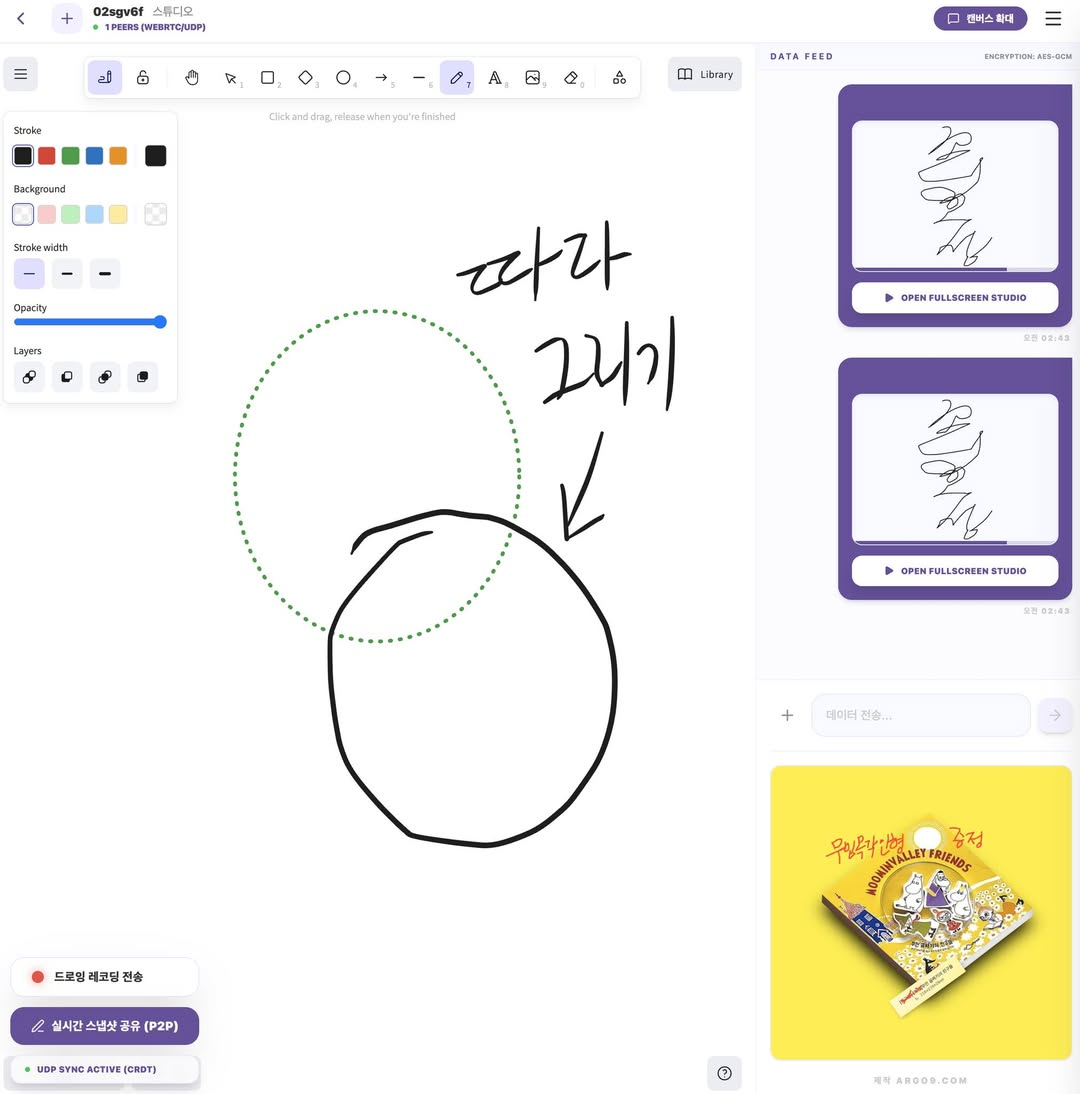
이제 대충 필기체용 폰트에디터겸 만화폰트, 애니메이션 효과음, 사인 등 기타등등 다 되는걸 끝냈습니다.https://chat.argo9.com/ 낙서가 자산이 되는 곳, 웹 기반 드로잉 & 폰트 크리에이터“당신의 손글씨와 낙서, 종이에만 남겨두기엔 너무 아깝지 않나요?” 이제 종이 위의 필사(筆寫) 놀이를 웹으로 가져오세요. 단순히 따라 그리는 …

우리회사 브랜드가 많아서 사이트를 완전히 재구성을 하다가 유튜브에 책이 자동으로 순위가 나오는 서가를 만드는 중입니다. 어떤출판사 책이건 상관없…지만 내가 꼭 그래야 하려나… https://www.youtube.com/watch?v=MiJhNiYxm54&feature=youtu.be 유튜브 라이브용 3D 책장 생성기: 필요해서 직접 만들었습니다 매번 유튜브 라이브나 도서 소개 영상을 만들 때마다 느꼈던 …